通过runtime的源码跟踪alloc,最终我们发现会调用libmalloc中的calloc方法,那么calloc做了什么呢,让我们来一探究竟
前言
本文将从runtime的alloc的最后流程讲起,为了方便回忆,先放一张runtime 创建实例的流程图。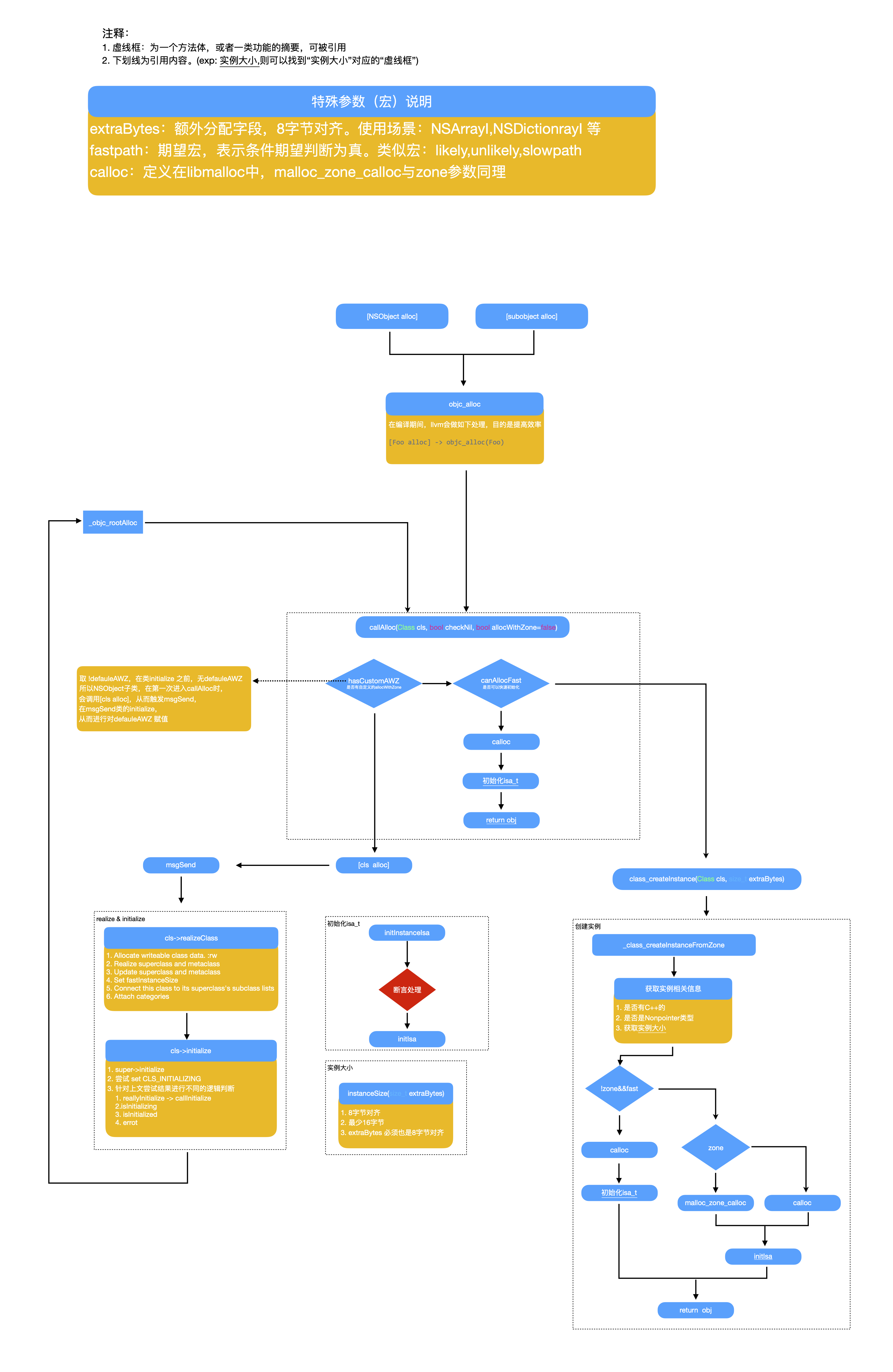 。
。
重上面的图片我们看出 runtime的最终会调用calloc,而calloc方法被定义在libmalloc中。
本文使用的libmalloc 源码版本为 libmalloc-166.251.2 版本。
malloc_zone_t
先来看一个十分重要的机构体1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37typedef struct _malloc_zone_t {
/* Only zone implementors should depend on the layout of this structure;
Regular callers should use the access functions below */
void *reserved1; /* RESERVED FOR CFAllocator DO NOT USE */
void *reserved2; /* RESERVED FOR CFAllocator DO NOT USE */
size_t (* MALLOC_ZONE_FN_PTR(size))(struct _malloc_zone_t *zone, const void *ptr); /* returns the size of a block or 0 if not in this zone; must be fast, especially for negative answers */
void *(* MALLOC_ZONE_FN_PTR(malloc))(struct _malloc_zone_t *zone, size_t size);
void *(* MALLOC_ZONE_FN_PTR(calloc))(struct _malloc_zone_t *zone, size_t num_items, size_t size); /* same as malloc, but block returned is set to zero */
void *(* MALLOC_ZONE_FN_PTR(valloc))(struct _malloc_zone_t *zone, size_t size); /* same as malloc, but block returned is set to zero and is guaranteed to be page aligned */
void (* MALLOC_ZONE_FN_PTR(free))(struct _malloc_zone_t *zone, void *ptr);
void *(* MALLOC_ZONE_FN_PTR(realloc))(struct _malloc_zone_t *zone, void *ptr, size_t size);
void (* MALLOC_ZONE_FN_PTR(destroy))(struct _malloc_zone_t *zone); /* zone is destroyed and all memory reclaimed */
const char *zone_name;
/* Optional batch callbacks; these may be NULL */
unsigned (* MALLOC_ZONE_FN_PTR(batch_malloc))(struct _malloc_zone_t *zone, size_t size, void **results, unsigned num_requested); /* given a size, returns pointers capable of holding that size; returns the number of pointers allocated (maybe 0 or less than num_requested) */
void (* MALLOC_ZONE_FN_PTR(batch_free))(struct _malloc_zone_t *zone, void **to_be_freed, unsigned num_to_be_freed); /* frees all the pointers in to_be_freed; note that to_be_freed may be overwritten during the process */
struct malloc_introspection_t * MALLOC_INTROSPECT_TBL_PTR(introspect);
unsigned version;
/* aligned memory allocation. The callback may be NULL. Present in version >= 5. */
void *(* MALLOC_ZONE_FN_PTR(memalign))(struct _malloc_zone_t *zone, size_t alignment, size_t size);
/* free a pointer known to be in zone and known to have the given size. The callback may be NULL. Present in version >= 6.*/
void (* MALLOC_ZONE_FN_PTR(free_definite_size))(struct _malloc_zone_t *zone, void *ptr, size_t size);
/* Empty out caches in the face of memory pressure. The callback may be NULL. Present in version >= 8. */
size_t (* MALLOC_ZONE_FN_PTR(pressure_relief))(struct _malloc_zone_t *zone, size_t goal);
/*
* Checks whether an address might belong to the zone. May be NULL. Present in version >= 10.
* False positives are allowed (e.g. the pointer was freed, or it's in zone space that has
* not yet been allocated. False negatives are not allowed.
*/
boolean_t (* MALLOC_ZONE_FN_PTR(claimed_address))(struct _malloc_zone_t *zone, void *ptr);
} malloc_zone_t;
malloc_zone_t是一个非常基础结构,里面包含一堆函数指针,用来存储一堆相关的处理函数的具体实现的地址,例如malloc、free、realloc等函数的具体实现。后续会基于malloc_zone_t进行扩展。
calloc
在runtime 的alloc阶段的最后调用的calloc函数实现如下。1
2
3
4
5
6
7
8
9
10
11void *
calloc(size_t num_items, size_t size)
{
void *retval;
// 这个default_zone 是重点关注的对象
retval = malloc_zone_calloc(default_zone, num_items, size);
if (retval == NULL) {
errno = ENOMEM;
}
return retval;
}
default_zone 引导
这个default_zone其实是一个“假的”zone,同时它也是malloc_zone_t类型。它存在的目的就是要引导程序进入一个创建真正的zone 的流程。下面来看一下default_zone的引导流程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20void *
malloc_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size)
{
MALLOC_TRACE(TRACE_calloc | DBG_FUNC_START, (uintptr_t)zone, num_items, size, 0);
void *ptr;
if (malloc_check_start && (malloc_check_counter++ >= malloc_check_start)) {
internal_check();
}
//此时传进来的 zone的类型是 上面calloc 传入的 defaultzone,所以zone->calloc的调用实现要看defaultzone 的定义。
ptr = zone->calloc(zone, num_items, size);
if (malloc_logger) {
malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE | MALLOC_LOG_TYPE_CLEARED, (uintptr_t)zone,
(uintptr_t)(num_items * size), 0, (uintptr_t)ptr, 0);
}
MALLOC_TRACE(TRACE_calloc | DBG_FUNC_END, (uintptr_t)zone, num_items, size, (uintptr_t)ptr);
return ptr;
}
defaultzone 的定义1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24static virtual_default_zone_t virtual_default_zone
__attribute__((section("__DATA,__v_zone")))
__attribute__((aligned(PAGE_MAX_SIZE))) = {
NULL,
NULL,
default_zone_size,
default_zone_malloc,
default_zone_calloc,//calloc的实现。
default_zone_valloc,
default_zone_free,
default_zone_realloc,
default_zone_destroy,
DEFAULT_MALLOC_ZONE_STRING,
default_zone_batch_malloc,
default_zone_batch_free,
&default_zone_introspect,
10,
default_zone_memalign,
default_zone_free_definite_size,
default_zone_pressure_relief,
default_zone_malloc_claimed_address,
};
static malloc_zone_t *default_zone = &virtual_default_zone.malloc_zone;
从上面的结构可以看出 defaultzone->calloc实际的函数实现为default_zone_calloc。1
2
3
4
5
6
7
8static void *
default_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size)
{
//引导创建真正的 zone。
zone = runtime_default_zone();
//使用真正的zone 进行calloc
return zone->calloc(zone, num_items, size);
}
zone
在创建正在的zone时,其实系统是有对应的一套创建策略的。在跟踪runtime_default_zone方法后,最终会进入如下调用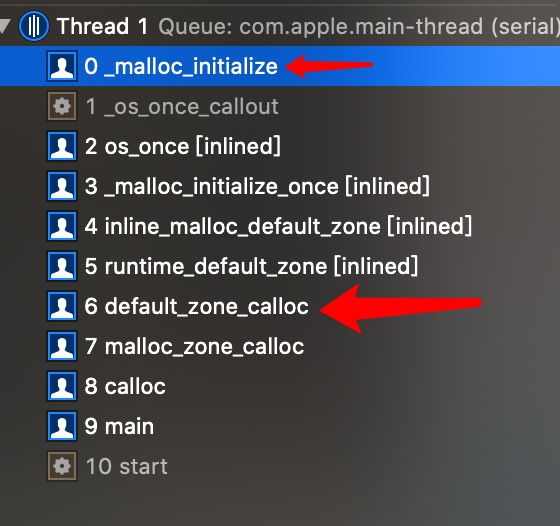
1 | static void |
在这里 会存在两种zone
- nanozone_t
- scalable_zone
nanozone_t
1 |
|
nanozone_t同样是malloc_zone_t类型。在nano_create_zone函数内部会完成对calloc等函数的重新赋值。
nano_create_zone
1 | malloc_zone_t * |
nano_calloc
过程参考defaultzone。回到上面default_zone_calloc函数内。下一步就是使用nanozone_t调用calloc。
下面是nano_calloc的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static void *
nano_calloc(nanozone_t *nanozone, size_t num_items, size_t size)
{
size_t total_bytes;
if (calloc_get_size(num_items, size, 0, &total_bytes)) {
return NULL;
}
// 如果要开辟的空间小于 NANO_MAX_SIZE 则进行nanozone_t的malloc。
if (total_bytes <= NANO_MAX_SIZE) {
void *p = _nano_malloc_check_clear(nanozone, total_bytes, 1);
if (p) {
return p;
} else {
/* FALLTHROUGH to helper zone */
}
}
//否则就进行helper_zone的流程
malloc_zone_t *zone = (malloc_zone_t *)(nanozone->helper_zone);
return zone->calloc(zone, 1, total_bytes);
}
_nano_malloc_check_clear
这里我们也可以看出使用nanozone_t的限制为不超过256B。继续看_nano_malloc_check_clear1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
static void *
_nano_malloc_check_clear(nanozone_t *nanozone, size_t size, boolean_t cleared_requested)
{
MALLOC_TRACE(TRACE_nano_malloc, (uintptr_t)nanozone, size, cleared_requested, 0);
void *ptr;
size_t slot_key;
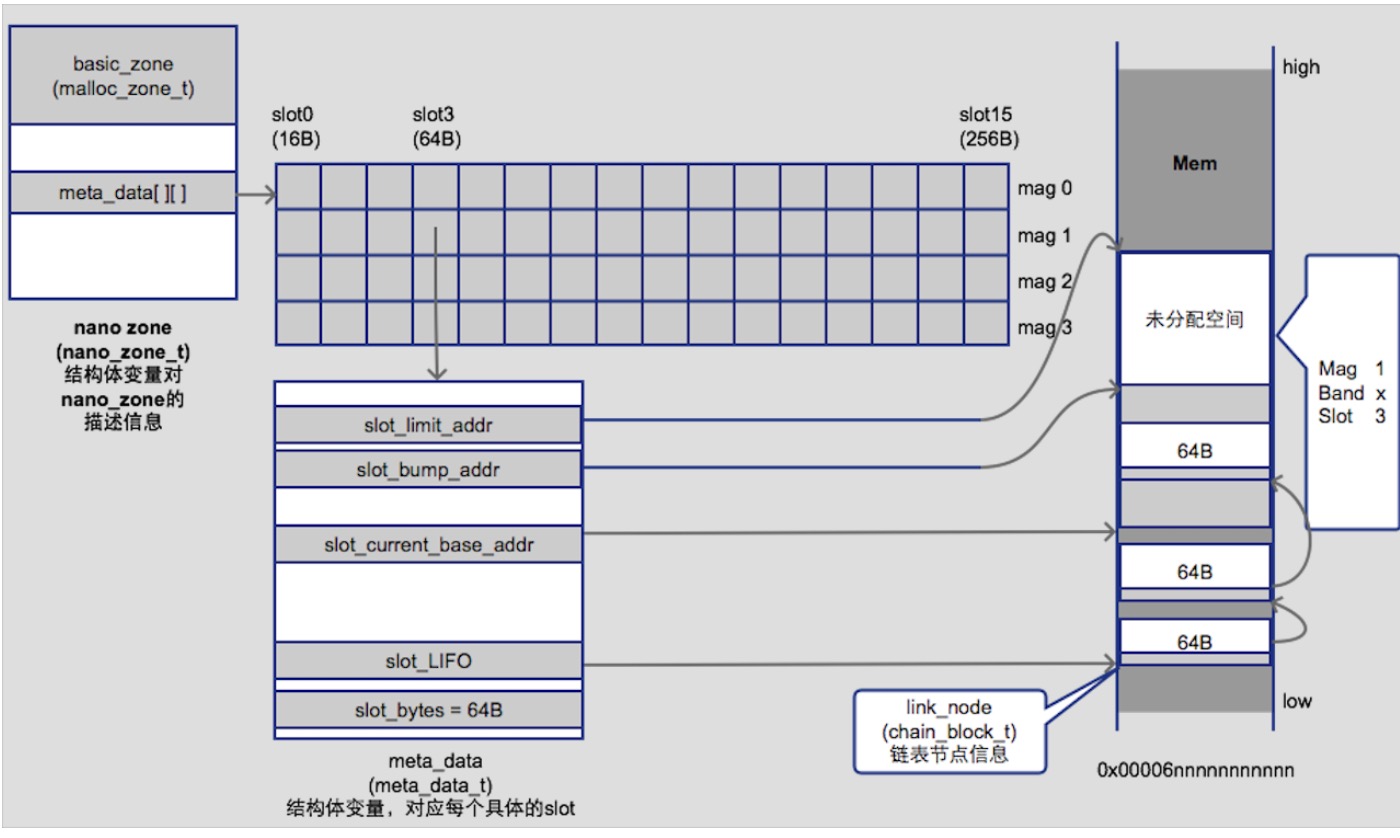
//获取16字节对齐之后的大小,slot_key非常关键,为slot_bytes/16的值,也是数组的二维下下标
size_t slot_bytes = segregated_size_to_fit(nanozone, size, &slot_key); // Note slot_key is set here
//根据_os_cpu_number经过运算获取 mag_index(meta_data的一维索引)
mag_index_t mag_index = nano_mag_index(nanozone);
//确定当前cpu对应的mag和通过size参数计算出来的slot,去对应metadata的链表中取已经被释放过的内存区块缓存
nano_meta_admin_t pMeta = &(nanozone->meta_data[mag_index][slot_key]);
//检测是否存在已经释放过,可以直接拿来用的内存,已经被释放的内存会缓存在 chained_block_s 链表
//每一次free。同样会根据 index 和slot 的值回去 pMeta,然后把slot_LIFO的指针指向释放的内存。
ptr = OSAtomicDequeue(&(pMeta->slot_LIFO), offsetof(struct chained_block_s, next));
if (ptr) {
...
//如果缓存的内存存在,这进行指针地址检查等异常检测,最后返回
//第一次调用malloc时,不会执行这一块代码。
} else {
//没有释放过的内存,所以调用函数 获取内存
ptr = segregated_next_block(nanozone, pMeta, slot_bytes, mag_index);
}
if (cleared_requested && ptr) {
memset(ptr, 0, slot_bytes); // TODO: Needs a memory barrier after memset to ensure zeroes land first?
}
return ptr;
}
该方法主要是通过cpu与slot确定index,从chained_block_s链表中找出是否存在已经释放过的缓存。如果存在则进行指针检查之后返回,否则进入查询meta data或者开辟band。
segregated_next_block
1 | static MALLOC_INLINE void * |
如果是第一次调用segregated_next_block函数,band不存在,缓存也不会存在,所以会调用segregated_band_grow。来开辟新的band
segregated_band_grow
1 | boolean_t |
当进入segregated_band_grow时,如果当前的band不够用,则使用 mach_vm_map经由pmap重新映射物理内存到虚拟内存。
关于通过nano_blk_addr_t的联合体结构如下,其每个成员所占的bit位数已经写出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct nano_blk_addr_s {
uint64_t
nano_offset:NANO_OFFSET_BITS, //17 locates the block
nano_slot:NANO_SLOT_BITS, //4 bucket of homogenous quanta-multiple blocks
nano_band:NANO_BAND_BITS, //17
nano_mag_index:NANO_MAG_BITS, //6 the core that allocated this block
nano_signature:NANOZONE_SIGNATURE_BITS; // the address range devoted to us.
};
#endif
// clang-format on
typedef union {
uint64_t addr;
struct nano_blk_addr_s fields;
} nano_blk_addr_t;
结合下面的例子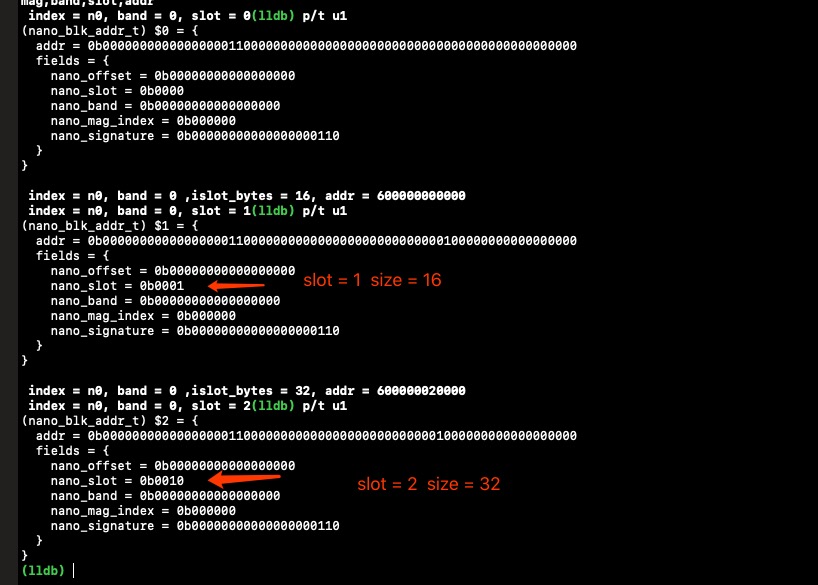
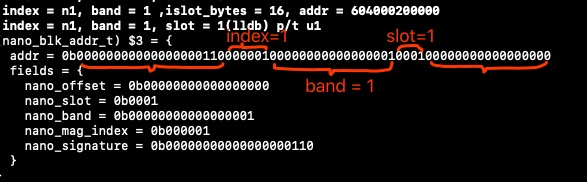
在free的阶段,也是使用如上的方式获取 对应的 slot,mag_index。
下面来梳理下nana_zone分配过程:
确定当前cpu对应的mag和通过size参数计算出来的slot,去对应
chained_block_s的链表中取已经被释放过的内存区块缓存,如果取到检查指针地址是否有问题,没有问题就直接返回;
初次进行nano malloc时,nano zon并没有缓存,会直接在nano zone范围的地址空间上直接分配连续地址内存;
如当前Band中当前Slot耗尽则向系统申请新的Band(每个Band固定大小2M,容纳了16个128k的槽),连续地址分配内存的基地址、limit地址以及当前分配到的地址由meta data结构维护起来,而这些meta data则以Mag、Slot为维度(Mag个数是处理器个数,Slot是16个)的二维数组形式,放在nanozone_t的meta_data字段中。
流程如下
scalable zone(helper_zone)
在szone上分配的内存包括tiny、small和large三大类,其中tiny和small的分配、释放过程大致相同,large类型有自己的方式管理。同样会通过create_scalable_zone来构造zone。
这里不在复述create_scalable_zone,直接看内存的分配策略
szone_malloc_should_clear
1 | MALLOC_NOINLINE void * |
这里以看出在szone上分配的内存包括tiny、small和large三大类,我们以tiny为例
tiny_malloc_should_clear
1 | void * |
每次调用free函数,会直接把要释放的内存优先放到mag_last_free指针上,在下次alloc时,也会优先检查mag_last_free 是否存在大小相等的内存,如果存在就直接返回。
tiny_malloc_from_free_list
这个函数的作用是从 free_list中不断进行各种策略尝试。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208void *
tiny_malloc_from_free_list(rack_t *rack, magazine_t *tiny_mag_ptr, mag_index_t mag_index, msize_t msize)
{
tiny_free_list_t *ptr;
msize_t this_msize;
grain_t slot = tiny_slot_from_msize(msize);
// free list 的首地址(第一个元素的地址)
free_list_t *free_list = tiny_mag_ptr->mag_free_list;
// 在首地址基础上偏移 slot 个元素。相当于free_list[slot]
free_list_t *the_slot = free_list + slot;
tiny_free_list_t *next;
free_list_t *limit;
#if defined(__LP64__)
uint64_t bitmap;
#else
uint32_t bitmap;
#endif
msize_t leftover_msize;
tiny_free_list_t *leftover_ptr;
// Assumes we've locked the region
CHECK_MAGAZINE_PTR_LOCKED(szone, tiny_mag_ptr, __PRETTY_FUNCTION__);
// Look for an exact match by checking the freelist for this msize.
//策略1.
//查找free list中当前请求大小区块的空闲缓存列表,如果有返回,并整理列表。
ptr = the_slot->p;
if (ptr) {
next = free_list_unchecksum_ptr(rack, &ptr->next);
if (next) {
next->previous = ptr->previous;
} else {
BITMAPV_CLR(tiny_mag_ptr->mag_bitmap, slot);
}
the_slot->p = next;
this_msize = msize;
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO, "in tiny_malloc_from_free_list(), exact match ptr=%p, this_msize=%d\n", ptr, this_msize);
}
#endif
goto return_tiny_alloc;
}
// Mask off the bits representing slots holding free blocks smaller than the
// size we need. If there are no larger free blocks, try allocating from
// the free space at the end of the tiny region.
#if defined(__LP64__)
bitmap = ((uint64_t *)(tiny_mag_ptr->mag_bitmap))[0] & ~((1ULL << slot) - 1);
#else
bitmap = tiny_mag_ptr->mag_bitmap[0] & ~((1 << slot) - 1);
#endif
if (!bitmap) {
goto try_tiny_malloc_from_end;
}
slot = BITMAPV_CTZ(bitmap);
limit = free_list + NUM_TINY_SLOTS;
free_list += slot;
if (free_list < limit) {
ptr = free_list->p;
if (ptr) {
next = free_list_unchecksum_ptr(rack, &ptr->next);
free_list->p = next;
if (next) {
next->previous = ptr->previous;
} else {
BITMAPV_CLR(tiny_mag_ptr->mag_bitmap, slot);
}
this_msize = get_tiny_free_size(ptr);
goto add_leftover_and_proceed;
}
#if DEBUG_MALLOC
malloc_report(ASL_LEVEL_ERR, "in tiny_malloc_from_free_list(), mag_bitmap out of sync, slot=%d\n", slot);
#endif
}
// We are now looking at the last slot, which contains blocks equal to, or
// due to coalescing of free blocks, larger than NUM_TINY_SLOTS * tiny quantum size.
// If the last freelist is not empty, and the head contains a block that is
// larger than our request, then the remainder is put back on the free list.
ptr = limit->p;
//策略2.
//在free list找比当前申请区块大的,而且最接近的缓存,如果有返回,并把剩余大小放到free list中另外的链表上。
if (ptr) {
//获取一个比申请的size 大的
this_msize = get_tiny_free_size(ptr);
next = free_list_unchecksum_ptr(rack, &ptr->next);
if (this_msize - msize > NUM_TINY_SLOTS) {
// the leftover will go back to the free list, so we optimize by
// modifying the free list rather than a pop and push of the head
leftover_msize = this_msize - msize;
leftover_ptr = (tiny_free_list_t *)((unsigned char *)ptr + TINY_BYTES_FOR_MSIZE(msize));
limit->p = leftover_ptr;
if (next) {
next->previous.u = free_list_checksum_ptr(rack, leftover_ptr);
}
leftover_ptr->previous = ptr->previous;
leftover_ptr->next = ptr->next;
//把多余的size 重新放回freelist
set_tiny_meta_header_free(leftover_ptr, leftover_msize);
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO,
"in tiny_malloc_from_free_list(), last slot ptr=%p, msize=%d this_msize=%d\n", ptr, msize, this_msize);
}
#endif
this_msize = msize;
goto return_tiny_alloc;
}
if (next) {
next->previous = ptr->previous;
}
limit->p = next;
goto add_leftover_and_proceed;
/* NOTREACHED */
}
try_tiny_malloc_from_end:
// Let's see if we can use tiny_mag_ptr->mag_bytes_free_at_end
//策略3.
//尝试在最后一个 region 开辟内存
if (tiny_mag_ptr->mag_bytes_free_at_end >= TINY_BYTES_FOR_MSIZE(msize)) {
//
uintptr_t tendptr = (uintptr_t)TINY_REGION_END(tiny_mag_ptr->mag_last_region);
ptr = (tiny_free_list_t *)(tendptr - tiny_mag_ptr->mag_bytes_free_at_end);
//更新最后一个region 没有使用的size 16的倍数
tiny_mag_ptr->mag_bytes_free_at_end -= TINY_BYTES_FOR_MSIZE(msize);
if (tiny_mag_ptr->mag_bytes_free_at_end) {
// let's add an in use block after ptr to serve as boundary
set_tiny_meta_header_in_use_1((unsigned char *)ptr + TINY_BYTES_FOR_MSIZE(msize));
}
this_msize = msize;
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO, "in tiny_malloc_from_free_list(), from end ptr=%p, msize=%d\n", ptr, msize);
}
#endif
goto return_tiny_alloc;
}
#if CONFIG_ASLR_INTERNAL
//策略4.
//尝试在在第一个 region 开辟内存
// Try from start if nothing left at end
if (tiny_mag_ptr->mag_bytes_free_at_start >= TINY_BYTES_FOR_MSIZE(msize)) {
ptr = (tiny_free_list_t *)(TINY_REGION_ADDRESS(tiny_mag_ptr->mag_last_region) + tiny_mag_ptr->mag_bytes_free_at_start -
TINY_BYTES_FOR_MSIZE(msize));
tiny_mag_ptr->mag_bytes_free_at_start -= TINY_BYTES_FOR_MSIZE(msize);
if (tiny_mag_ptr->mag_bytes_free_at_start) {
// let's add an in use block before ptr to serve as boundary
set_tiny_meta_header_in_use_1((unsigned char *)ptr - TINY_QUANTUM);
}
this_msize = msize;
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO, "in tiny_malloc_from_free_list(), from start ptr=%p, msize=%d\n", ptr, msize);
}
#endif
goto return_tiny_alloc;
}
#endif
return NULL;
add_leftover_and_proceed:
if (!this_msize || (this_msize > msize)) {
leftover_msize = this_msize - msize;
leftover_ptr = (tiny_free_list_t *)((unsigned char *)ptr + TINY_BYTES_FOR_MSIZE(msize));
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO, "in tiny_malloc_from_free_list(), adding leftover ptr=%p, this_msize=%d\n", ptr, this_msize);
}
#endif
tiny_free_list_add_ptr(rack, tiny_mag_ptr, leftover_ptr, leftover_msize);
this_msize = msize;
}
return_tiny_alloc:
tiny_mag_ptr->mag_num_objects++;
tiny_mag_ptr->mag_num_bytes_in_objects += TINY_BYTES_FOR_MSIZE(this_msize);
// Update this region's bytes in use count
//根据ptr换算出node
region_trailer_t *node = REGION_TRAILER_FOR_TINY_REGION(TINY_REGION_FOR_PTR(ptr));
size_t bytes_used = node->bytes_used + TINY_BYTES_FOR_MSIZE(this_msize);
node->bytes_used = (unsigned int)bytes_used;
// Emptiness discriminant
if (bytes_used < DENSITY_THRESHOLD(TINY_REGION_PAYLOAD_BYTES)) {
/* After this allocation the region is still sparse, so it must have been even more so before
* the allocation. That implies the region is already correctly marked. Do nothing. */
} else {
/* Region has crossed threshold from sparsity to density. Mark it not "suitable" on the
* recirculation candidates list. */
node->recirc_suitable = FALSE;
}
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO, "in tiny_malloc_from_free_list(), ptr=%p, this_msize=%d, msize=%d\n", ptr, this_msize, msize);
}
#endif
if (this_msize > 1) {
set_tiny_meta_header_in_use(ptr, this_msize);
} else {
set_tiny_meta_header_in_use_1(ptr);
}
return ptr;
}
从上面的流程可以看出,在查找已经释放的内存缓存,会采用2步缓存查找(策略1,2),及两步备用内存的开辟(策略3,4)。
当free_list流程仍然找不到可以使用内存,就会使用tiny_get_region_from_depot
tiny_get_region_from_depot
1 | static boolean_t |
每一个类型的rack指向的magazines,都会在下标为-1magazine_t当做备用:depot,该方法的作用是从备用的depot查找出是否有满足条件的region如果存在,更新depot和region的关联关系,然后在关联当前的magazine_t和region。之后在再次重复free_list过程。
mvm_allocate_pages_securely
走到这一步,就需要申请新的heap了,这里需要理解虚拟内存和物理内存的映射关系。
你其实只要记住两点:vm_map代表就是一个进程运行时候涉及的虚拟内存,pmap代表的就是和具体硬件架构相关的物理内存。
重新申请的核心函数为mach_vm_map,其概念如图
tiny_malloc_from_region_no_lock
重新申请了新的内存(region)之后,挂载到当前的magazine下并分配内存。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85static void *
tiny_malloc_from_region_no_lock(rack_t *rack,
magazine_t *tiny_mag_ptr,
mag_index_t mag_index,
msize_t msize,
void *aligned_address)
{
void *ptr;
// Deal with unclaimed memory -- mag_bytes_free_at_end or mag_bytes_free_at_start
if (tiny_mag_ptr->mag_bytes_free_at_end || tiny_mag_ptr->mag_bytes_free_at_start) {
tiny_finalize_region(rack, tiny_mag_ptr);
}
// We set the unused bits of the header in the last pair to be all ones, and those of the inuse to zeroes.
#if NUM_TINY_BLOCKS & 31
const uint32_t header = 0xFFFFFFFFU << (NUM_TINY_BLOCKS & 31);
#else
const uint32_t header = 0;
#endif
//把新申请的内存地址转化为 region
tiny_region_t trt = (tiny_region_t)aligned_address;
((tiny_region_t)aligned_address)->pairs[CEIL_NUM_TINY_BLOCKS_WORDS - 1].header = header;
((tiny_region_t)aligned_address)->pairs[CEIL_NUM_TINY_BLOCKS_WORDS - 1].inuse = 0;
// Tag the region at "aligned_address" as belonging to us,
// and so put it under the protection of the magazine lock we are holding.
// Do this before advertising "aligned_address" on the hash ring(!)
//把region 的地址和当前的mag_index 关联起来,因为在calloc时,就是要根据不同的index 获取magazine,
//在根据magazine拿到关联的 region
MAGAZINE_INDEX_FOR_TINY_REGION(aligned_address) = mag_index;
// Insert the new region into the hash ring
rack_region_insert(rack, (region_t)aligned_address);
tiny_mag_ptr->mag_last_region = aligned_address;
BYTES_USED_FOR_TINY_REGION(aligned_address) = TINY_BYTES_FOR_MSIZE(msize);
#if CONFIG_ASLR_INTERNAL
int offset_msize = malloc_entropy[0] & TINY_ENTROPY_MASK;
#if DEBUG_MALLOC
if (getenv("MallocASLRForce")) {
offset_msize = strtol(getenv("MallocASLRForce"), NULL, 0) & TINY_ENTROPY_MASK;
}
if (getenv("MallocASLRPrint")) {
malloc_report(ASL_LEVEL_INFO, "Region: %p offset: %d\n", aligned_address, offset_msize);
}
#endif
#else
int offset_msize = 0;
#endif
uintptr_t ads = (uintptr_t)aligned_address;
uintptr_t om = TINY_BYTES_FOR_MSIZE(offset_msize);
ptr = (void *)(ads + om);
set_tiny_meta_header_in_use(ptr, msize);
//更新当前magazine 的相关信息
tiny_mag_ptr->mag_num_objects++;
tiny_mag_ptr->mag_num_bytes_in_objects += TINY_BYTES_FOR_MSIZE(msize);
tiny_mag_ptr->num_bytes_in_magazine += TINY_REGION_PAYLOAD_BYTES;
// We put a header on the last block so that it appears in use (for coalescing, etc...)
set_tiny_meta_header_in_use_1((void *)((uintptr_t)ptr + TINY_BYTES_FOR_MSIZE(msize)));
tiny_mag_ptr->mag_bytes_free_at_end = TINY_BYTES_FOR_MSIZE(NUM_TINY_BLOCKS - msize - offset_msize);
#if CONFIG_ASLR_INTERNAL
// Put a header on the previous block for same reason
tiny_mag_ptr->mag_bytes_free_at_start = TINY_BYTES_FOR_MSIZE(offset_msize);
if (offset_msize) {
set_tiny_meta_header_in_use_1((void *)((uintptr_t)ptr - TINY_QUANTUM));
}
#else
tiny_mag_ptr->mag_bytes_free_at_start = 0;
#endif
// connect to magazine as last node
//关联到magazine
recirc_list_splice_last(rack, tiny_mag_ptr, REGION_TRAILER_FOR_TINY_REGION(aligned_address));
#if DEBUG_MALLOC
if (LOG(szone, ptr)) {
malloc_report(ASL_LEVEL_INFO, "in tiny_malloc_from_region_no_lock(), ptr=%p, msize=%d\n", ptr, msize);
}
#endif
return ptr;
}
这个方法的主要作用是把新申请的内存地址,转换为region,并进行相关的关联。及更新对应的magazine。整个scalable_zone的结构体关系,及流程如下
free
对于free操作同样会选择对应的zone 进行
nano_zone
malloc库会检查指针地址,如果没有问题,则以链表的形式将这些区块按大小存储起来。这些链表的头部放在meta_data数组中对应的[mag][slot]元素中。
其实从缓存获取空余内存和释放内存时都会对指向这篇内存区域的指针进行检查,如果有类似地址不对齐、未释放/多次释放、所属地址与预期的mag、slot不匹配等情况都会以报错结束。
scalable_zone
首先检查指针指向地址是否有问题。
如果last free指针上没有挂载内存区块,则放到last free上。
如果有last free,置换内存,并把last free原有内存区块挂载到free list上(在挂载的free list前,会先根据region位图检查前后区块是否能合并成更大区块,如果能会合并成一个)。
合并后所在的region如果空闲字节超过一定条件,则将把此region放到后备的magazine中(-1)。
如果整个region都是空的,则直接还给系统内核。
流程总结

其他
设计
malloc_zone_t提供了一个模板类,或者理解为malloc_zone_t提供一类接口(高度抽象了alloc一个对象所需要的特征),free,calloc等。
由所有拓展的结构体来实现真正的目标函数。
同上对于上层Objc,提供了抽象接口(依赖倒置),这样就降低了调用者(Objc)与实现模块间的耦合。