GCD系列 文章之线程同步与组,建议顺序为:概念,原理,之后在阅读本文
背景
源码及版本号。所有源码均在苹果开源官网下可下载
源码 | 版本
-|-
libdispatch | 1008.250.7
libpthread | 330.250.2
xnu | 6153.11.26
barrier
在就讲过之前的sync和async之后,barrier函数就相对好理解了
sync
dispatch_barrier_sync和dispatch_sync组合串行队列的流程相似,由于同步操作,当前面的任务执行时,后面任务会进入wait流程,关于等待与唤醒的方式,在前一篇已经有过说明。
async
dispatch_barrier_async和dispatch_async有所不同,在配合并行队列的情况下:经由_dispatch_lane_concurrent_push会进入到_dispatch_lane_push(回忆上篇异步并行的流程)。
1 |
|
这里最终会调用到dx_wakeup即:_dispatch_lane_wakeup。
这个函数内部会调用_dispatch_queue_wakeup。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101void
_dispatch_queue_wakeup(dispatch_queue_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target)
{
dispatch_queue_t dq = dqu._dq;
dispatch_assert(target != DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT);
if (target && !(flags & DISPATCH_WAKEUP_CONSUME_2)) {
_dispatch_retain_2(dq);
flags |= DISPATCH_WAKEUP_CONSUME_2;
}
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
//
// _dispatch_lane_class_barrier_complete() is about what both regular
// queues and sources needs to evaluate, but the former can have sync
// handoffs to perform which _dispatch_lane_class_barrier_complete()
// doesn't handle, only _dispatch_lane_barrier_complete() does.
//
// _dispatch_lane_wakeup() is the one for plain queues that calls
// _dispatch_lane_barrier_complete(), and this is only taken for non
// queue types.
//
dispatch_assert(dx_metatype(dq) == _DISPATCH_SOURCE_TYPE);
qos = _dispatch_queue_wakeup_qos(dq, qos);
return _dispatch_lane_class_barrier_complete(upcast(dq)._dl, qos,
flags, target, DISPATCH_QUEUE_SERIAL_DRAIN_OWNED);
}
//barrier 会这走这里。
if (target) {
uint64_t old_state, new_state, enqueue = DISPATCH_QUEUE_ENQUEUED;
if (target == DISPATCH_QUEUE_WAKEUP_MGR) {
enqueue = DISPATCH_QUEUE_ENQUEUED_ON_MGR;
}
qos = _dispatch_queue_wakeup_qos(dq, qos);
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = _dq_state_merge_qos(old_state, qos);
if (likely(!_dq_state_is_suspended(old_state) &&
!_dq_state_is_enqueued(old_state) &&
(!_dq_state_drain_locked(old_state) ||
(enqueue != DISPATCH_QUEUE_ENQUEUED_ON_MGR &&
_dq_state_is_base_wlh(old_state))))) {
new_state |= enqueue;
}
if (flags & DISPATCH_WAKEUP_MAKE_DIRTY) {
new_state |= DISPATCH_QUEUE_DIRTY;
} else if (new_state == old_state) {
os_atomic_rmw_loop_give_up(goto done);
}
});
if (likely((old_state ^ new_state) & enqueue)) {
dispatch_queue_t tq;
if (target == DISPATCH_QUEUE_WAKEUP_TARGET) {
// the rmw_loop above has no acquire barrier, as the last block
// of a queue asyncing to that queue is not an uncommon pattern
// and in that case the acquire would be completely useless
//
// so instead use depdendency ordering to read
// the targetq pointer.
os_atomic_thread_fence(dependency);
tq = os_atomic_load_with_dependency_on2o(dq, do_targetq,
(long)new_state);
} else {
tq = target;
}
dispatch_assert(_dq_state_is_enqueued(new_state));
return _dispatch_queue_push_queue(tq, dq, new_state);
}
#if HAVE_PTHREAD_WORKQUEUE_QOS
if (unlikely((old_state ^ new_state) & DISPATCH_QUEUE_MAX_QOS_MASK)) {
if (_dq_state_should_override(new_state)) {
return _dispatch_queue_wakeup_with_override(dq, new_state,
flags);
}
}
} else if (qos) {
//
// Someone is trying to override the last work item of the queue.
//
uint64_t old_state, new_state;
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, relaxed, {
if (!_dq_state_drain_locked(old_state) ||
!_dq_state_is_enqueued(old_state)) {
os_atomic_rmw_loop_give_up(goto done);
}
new_state = _dq_state_merge_qos(old_state, qos);
if (new_state == old_state) {
os_atomic_rmw_loop_give_up(goto done);
}
});
if (_dq_state_should_override(new_state)) {
return _dispatch_queue_wakeup_with_override(dq, new_state, flags);
}
#endif // HAVE_PTHREAD_WORKQUEUE_QOS
}
done:
if (likely(flags & DISPATCH_WAKEUP_CONSUME_2)) {
return _dispatch_release_2_tailcall(dq);
}
}
_dispatch_queue_push_queue会进一步调用_dispatch_root_queue_push在前一篇已经分析过流程,但是在barrier的异步流程中,并不会每次都开启新的线程。
接下来在看一下任务的执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147DISPATCH_NOINLINE
static dispatch_queue_wakeup_target_t
_dispatch_lane_concurrent_drain(dispatch_lane_class_t dqu,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
uint64_t *owned)
{
return _dispatch_lane_drain(dqu._dl, dic, flags, owned, false);
}
DISPATCH_ALWAYS_INLINE
static dispatch_queue_wakeup_target_t
_dispatch_lane_drain(dispatch_lane_t dq, dispatch_invoke_context_t dic,
dispatch_invoke_flags_t flags, uint64_t *owned_ptr, bool serial_drain)
{
dispatch_queue_t orig_tq = dq->do_targetq;
dispatch_thread_frame_s dtf;
struct dispatch_object_s *dc = NULL, *next_dc;
uint64_t dq_state, owned = *owned_ptr;
if (unlikely(!dq->dq_items_tail)) return NULL;
_dispatch_thread_frame_push(&dtf, dq);
if (serial_drain || _dq_state_is_in_barrier(owned)) {
// we really own `IN_BARRIER + dq->dq_width * WIDTH_INTERVAL`
// but width can change while draining barrier work items, so we only
// convert to `dq->dq_width * WIDTH_INTERVAL` when we drop `IN_BARRIER`
owned = DISPATCH_QUEUE_IN_BARRIER;
} else {
owned &= DISPATCH_QUEUE_WIDTH_MASK;
}
dc = _dispatch_queue_get_head(dq);
goto first_iteration;
for (;;) {
dispatch_assert(dic->dic_barrier_waiter == NULL);
dc = next_dc;
if (unlikely(_dispatch_needs_to_return_to_kernel())) {
_dispatch_return_to_kernel();
}
if (unlikely(!dc)) {
if (!dq->dq_items_tail) {
break;
}
dc = _dispatch_queue_get_head(dq);
}
if (unlikely(serial_drain != (dq->dq_width == 1))) {
break;
}
if (unlikely(_dispatch_queue_drain_should_narrow(dic))) {
break;
}
if (likely(flags & DISPATCH_INVOKE_WORKLOOP_DRAIN)) {
dispatch_workloop_t dwl = (dispatch_workloop_t)_dispatch_get_wlh();
if (unlikely(_dispatch_queue_max_qos(dwl) > dwl->dwl_drained_qos)) {
break;
}
}
first_iteration:
dq_state = os_atomic_load(&dq->dq_state, relaxed);
if (unlikely(_dq_state_is_suspended(dq_state))) {
break;
}
if (unlikely(orig_tq != dq->do_targetq)) {
break;
}
if (serial_drain || _dispatch_object_is_barrier(dc)) {
if (!serial_drain && owned != DISPATCH_QUEUE_IN_BARRIER) {
if (!_dispatch_queue_try_upgrade_full_width(dq, owned)) {
goto out_with_no_width;
}
owned = DISPATCH_QUEUE_IN_BARRIER;
}
if (_dispatch_object_is_sync_waiter(dc) &&
!(flags & DISPATCH_INVOKE_THREAD_BOUND)) {
dic->dic_barrier_waiter = dc;
goto out_with_barrier_waiter;
}
next_dc = _dispatch_queue_pop_head(dq, dc);
} else {
if (owned == DISPATCH_QUEUE_IN_BARRIER) {
// we just ran barrier work items, we have to make their
// effect visible to other sync work items on other threads
// that may start coming in after this point, hence the
// release barrier
os_atomic_xor2o(dq, dq_state, owned, release);
owned = dq->dq_width * DISPATCH_QUEUE_WIDTH_INTERVAL;
} else if (unlikely(owned == 0)) {
if (_dispatch_object_is_waiter(dc)) {
// sync "readers" don't observe the limit
_dispatch_queue_reserve_sync_width(dq);
} else if (!_dispatch_queue_try_acquire_async(dq)) {
goto out_with_no_width;
}
owned = DISPATCH_QUEUE_WIDTH_INTERVAL;
}
next_dc = _dispatch_queue_pop_head(dq, dc);
if (_dispatch_object_is_waiter(dc)) {
owned -= DISPATCH_QUEUE_WIDTH_INTERVAL;
_dispatch_non_barrier_waiter_redirect_or_wake(dq, dc);
continue;
}
if (flags & DISPATCH_INVOKE_REDIRECTING_DRAIN) {
owned -= DISPATCH_QUEUE_WIDTH_INTERVAL;
// This is a re-redirect, overrides have already been applied by
// _dispatch_continuation_async*
// However we want to end up on the root queue matching `dc`
// qos, so pick up the current override of `dq` which includes
// dc's override (and maybe more)
_dispatch_continuation_redirect_push(dq, dc,
_dispatch_queue_max_qos(dq));
continue;
}
}
_dispatch_continuation_pop_inline(dc, dic, flags, dq);
}
if (owned == DISPATCH_QUEUE_IN_BARRIER) {
// if we're IN_BARRIER we really own the full width too
owned += dq->dq_width * DISPATCH_QUEUE_WIDTH_INTERVAL;
}
if (dc) {
owned = _dispatch_queue_adjust_owned(dq, owned, dc);
}
*owned_ptr &= DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_ENQUEUED_ON_MGR;
*owned_ptr |= owned;
_dispatch_thread_frame_pop(&dtf);
return dc ? dq->do_targetq : NULL;
out_with_no_width:
*owned_ptr &= DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_ENQUEUED_ON_MGR;
_dispatch_thread_frame_pop(&dtf);
return DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT;
out_with_barrier_waiter:
if (unlikely(flags & DISPATCH_INVOKE_DISALLOW_SYNC_WAITERS)) {
DISPATCH_INTERNAL_CRASH(0,
"Deferred continuation on source, mach channel or mgr");
}
_dispatch_thread_frame_pop(&dtf);
return dq->do_targetq;
}
先来看一组log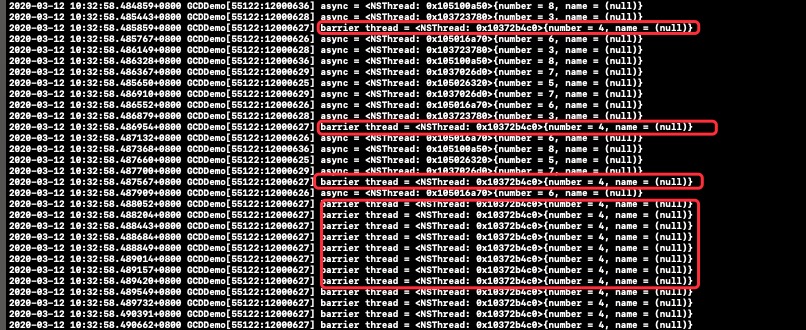
对于barrier的异步实现比较巧妙,首先我们来想一个问题,要实现这种“异步等待”的策略,必然要使得barrier_async那样具有wait的相关函数。
首先我们知道GCD的队列都是FIFO 的,那么是否可以开启一个专用的栅栏线程,来执行这个FIFO的队列,从而形成一个类似barrier的功能呢。再来解释一下,当只有一个线程来调度队列时,因为队列FIFO的特性,使得这个队列的任务执行都是按顺序(前一个任务执行完,再执行后一个)。
在异步并发的场景下,GCD的队列仍然遵循FIFO的规则,但是由于每一次dispatch_async都会开辟一个线程,因此会有多个线程来执行多个队列任务。
A concurrent dispatch queue is useful when you have multiple tasks that can run in parallel. A concurrent queue is still a queue in that it dequeues tasks in a first-in, first-out order; however, a concurrent queue may dequeue additional tasks before any previous tasks finish.
值得注意的一点:barrier对于全局队列无效。
barrier总结
在异步的场景,因为GCD队列是FIFO的,所以barrier_async只要保证只有一个线程在 执行block 就形成了 栅栏。
在同步场景下,barrier使用了和dispatch_sync一样的wait函数来实现同步。
但是barrier_sync不能采用类似barrier_async的做法:
- 同步函数没有开辟线程的能力。
- 同步是在当前线程执行栅栏,当前线程也有可能是多个异步(async 嵌套 sync 这样),因此这种情况下barrier_sync要有阻塞(wait)的能力。
semaphore
信号量是泛化的互斥体,互斥体只能是0和1,但信号量是:取值可以达到某个正数,即允许并发持有信号量的持有者的个数。
GCD的信号量也是基于 mach 信号。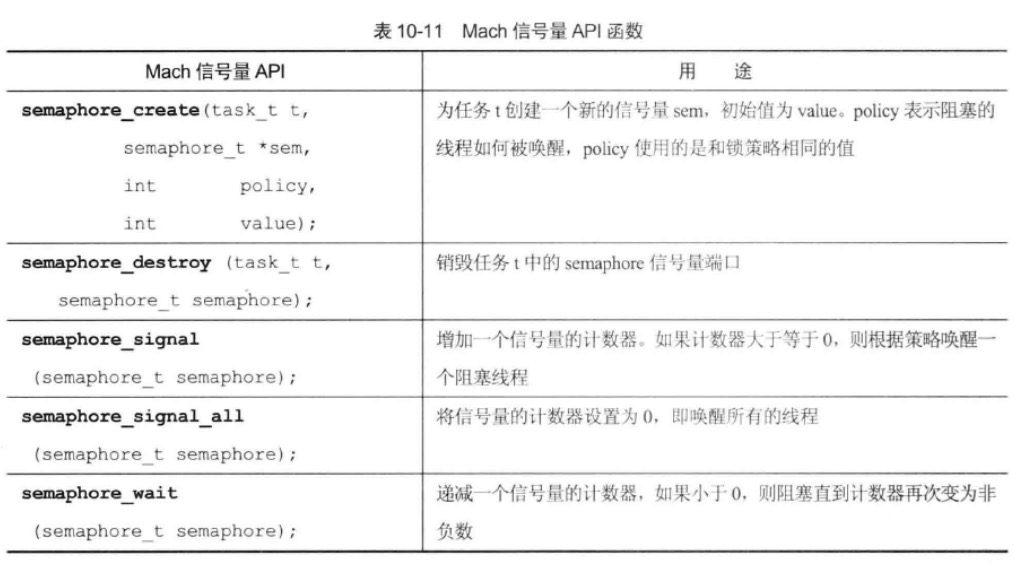
dispatch_semaphore_wait
1 | long |
dispatch_semaphore_wait会使信号量原子性-1,然后进行等待或直接返回,等待的策略如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30static long
_dispatch_semaphore_wait_slow(dispatch_semaphore_t dsema,
dispatch_time_t timeout)
{
long orig;
_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
switch (timeout) {
default:
if (!_dispatch_sema4_timedwait(&dsema->dsema_sema, timeout)) {
break;
}
// Fall through and try to undo what the fast path did to
// dsema->dsema_value
case DISPATCH_TIME_NOW:
orig = dsema->dsema_value;
while (orig < 0) {
if (os_atomic_cmpxchgvw2o(dsema, dsema_value, orig, orig + 1,
&orig, relaxed)) {
return _DSEMA4_TIMEOUT();
}
}
// Another thread called semaphore_signal().
// Fall through and drain the wakeup.
case DISPATCH_TIME_FOREVER:
_dispatch_sema4_wait(&dsema->dsema_sema);
break;
}
return 0;
}
根据timeout的参数不同,等待不同的时间,DISPATCH_TIME_FOREVER会调用_dispatch_sema4_wait。1
2
3
4
5
6
7
8
9void
_dispatch_sema4_wait(_dispatch_sema4_t *sema)
{
kern_return_t kr;
do {
kr = semaphore_wait(*sema);
} while (kr == KERN_ABORTED);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
}
与之配套的signal1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33DISPATCH_NOINLINE
long
_dispatch_semaphore_signal_slow(dispatch_semaphore_t dsema)
{
_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
_dispatch_sema4_signal(&dsema->dsema_sema, 1);
return 1;
}
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
long value = os_atomic_inc2o(dsema, dsema_value, release);
//如果当前有可用资源(信号量>0),则不作任何操作
if (likely(value > 0)) {
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
//需要发送信号量
return _dispatch_semaphore_signal_slow(dsema);
}
void
_dispatch_sema4_signal(_dispatch_sema4_t *sema, long count)
{
do {
kern_return_t kr = semaphore_signal(*sema);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
} while (--count);
}
信号量总体来说比较简单。值得注意的点就是当信号量销毁时,如果当前的信号值和初始值不一致,会引发crash1
2
3
4
5
6
7
8
9
10
11
12
13void
_dispatch_semaphore_dispose(dispatch_object_t dou,
DISPATCH_UNUSED bool *allow_free)
{
dispatch_semaphore_t dsema = dou._dsema;
if (dsema->dsema_value < dsema->dsema_orig) {
DISPATCH_CLIENT_CRASH(dsema->dsema_orig - dsema->dsema_value,
"Semaphore object deallocated while in use");
}
_dispatch_sema4_dispose(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
}
group
关于dispatch_group的定义在code>semaphore.c中,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20static inline dispatch_group_t
_dispatch_group_create_with_count(uint32_t n)
{
dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),
sizeof(struct dispatch_group_s));
dg->do_next = DISPATCH_OBJECT_LISTLESS;
dg->do_targetq = _dispatch_get_default_queue(false);
if (n) {
os_atomic_store2o(dg, dg_bits,
-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); // <rdar://22318411>
}
return dg;
}
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
group采用和信号量类似的思想,通过存储count的值来判断notify的操作。
而对应信号量的wait 和 signal有enterleave1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);
}
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
void
dispatch_group_enter(dispatch_group_t dg)
{
// The value is decremented on a 32bits wide atomic so that the carry
// for the 0 -> -1 transition is not propagated to the upper 32bits.
uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits,
DISPATCH_GROUP_VALUE_INTERVAL, acquire);
uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;
if (unlikely(old_value == 0)) {
_dispatch_retain(dg); // <rdar://problem/22318411>
}
if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) {
DISPATCH_CLIENT_CRASH(old_bits,
"Too many nested calls to dispatch_group_enter()");
}
}
总体来说group的实现方式比较简单,其中不乏借鉴了信号量的思想。
总结
API注意事项
多线程需要注意的点一个是多线程技术带来的数据竞争问题,一个是防止数据竞争带来的死锁问题。
死锁的条件
死锁的四个必要条件:
互斥条件:一个资源每次只能被一个进程使用,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)。
循环等待条件: 若干进程间形成首尾相接循环等待资源的关系。
对于GCD的同步API都应注意。
设计思想
架构分层
从GCD的整个流程扩展开来看,我们能够看到架构分层设计思想:Mach提供基础的原始API,由上层的BSD实现不同的功能扩展。 也包括libdispatch -> libpthread -> xnu的分层。
面向对象
在前面的malloc源码也见过同样的设计,只不过由原来的zone的继承,变成了GCD的结构体嵌套。为了时这些队列操作对象都具有相同的行为,采用了vtable的函数表设计,并关联在对应的结构体对象上,还有对应的类簇结构体。