本文主要探索锁的底层实现,如果你想知道锁是如何让一个线程主动让出时间片,那么就来看看吧
源码 | 版本
-|-
libpthread | 330.250.2
libplatform | 220
概念
公平锁
其实我们平时使用的锁(除了os_unfair_lock)基本都是公平锁,这一类锁有着FIFO的特性即:
多个线程情况下排队,先到先获得锁。
如果进入等待的顺序为12345,则最后等待结束被执行的顺序也是12345。
如图所示
非公平锁
当锁被释放后,所有线程竞争锁,抢到的线程就会获得锁。
在iOS 上的非公平锁为os_unfair_lock。
汇编
系统调用:
arm64汇编中使用svc #0x80来实现系统调用。
原子性的保证:
x86使用lock+指令(ADD,cmpxchg等)。
arm64使用LDXXX(LDADD)。
锁的实现
先从Foundation说起。Foundation 中的锁都是对POSXI中锁的封装,对应关系如下:
Foundation | POSIX
-|-
NSLock | pthread_mutex_t
NSRecursiveLock | pthread_mutex_t(Recursive)
示例代码
1 | for (int i = 0; i<10; i++) { |
这里一定要用printf或者更高效的方式,不可以使用NSLog1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20i = 0 is start wait
i = 0 is doing
i = 1 is start wait
i = 2 is start wait
i = 3 is start wait
i = 4 is start wait
i = 5 is start wait
i = 6 is start wait
i = 7 is start wait
i = 8 is start wait
i = 9 is start wait
i = 1 is doing
i = 3 is doing
i = 5 is doing
i = 4 is doing
i = 9 is doing
i = 8 is doing
i = 2 is doing
i = 7 is doing
i = 6 is doing
pthread_mutex_t
先来看互斥体的定义1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21typedef struct {
long sig;
_pthread_lock lock;
union {
uint32_t value;
struct _pthread_mutex_options options;//互斥体的一些可选属性,如:递归锁
} mtxopts;
int16_t prioceiling;
int16_t priority;
#if defined(__LP64__)
uint32_t _pad;
#endif
uint32_t m_tid[2]; // thread id of thread that has mutex locked
uint32_t m_seq[2]; // mutex sequence id
uint32_t m_mis[2]; // for misaligned locks m_tid/m_seq will span into here
#if defined(__LP64__)
uint32_t _reserved[4];
#else
uint32_t _reserved[1];
#endif
} _pthread_mutex;
对于锁的过程,我们可以通过system trace来查看一个线程的调度状态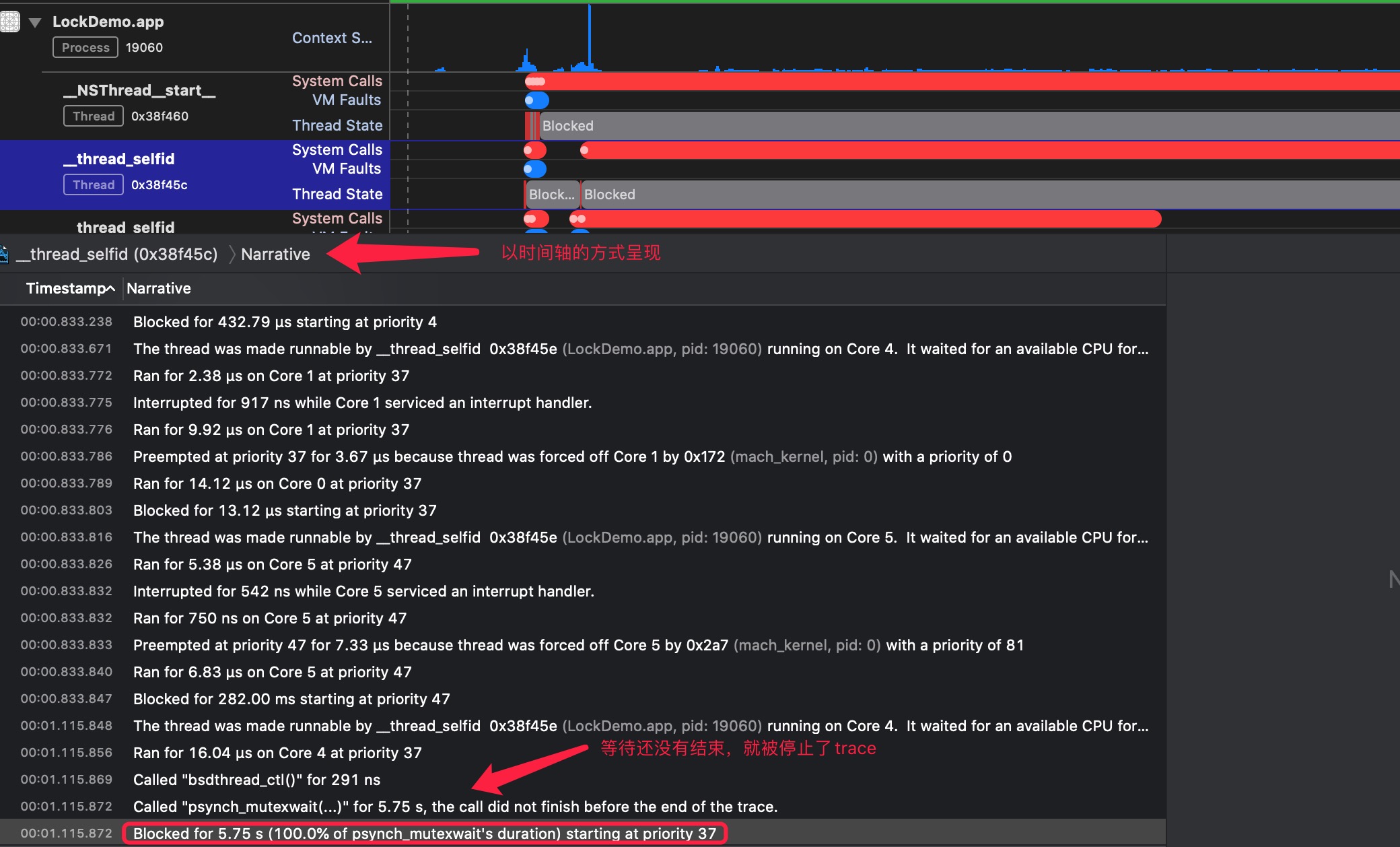
切换为线程调度状态
线程的状态说明:
- Running,线程在CPU上运行。
- Blocked,线程被挂起,原因有很多,比如等待锁,sleep,File Backed Page In等等。
- Runnable,线程处于可执行状态,等CPU空闲的时候,就可以运行
- Interrupted,被打断,通常是因为一些系统事件,一般不需要关注
- Preempted,被抢占,优先级更高的线程进入了Runnable状态
我们可以看到一个处于等待中的线程的调用栈: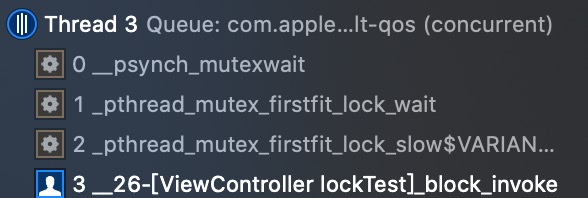
还有
我们亦可以通过IDA等反汇编工具来查看。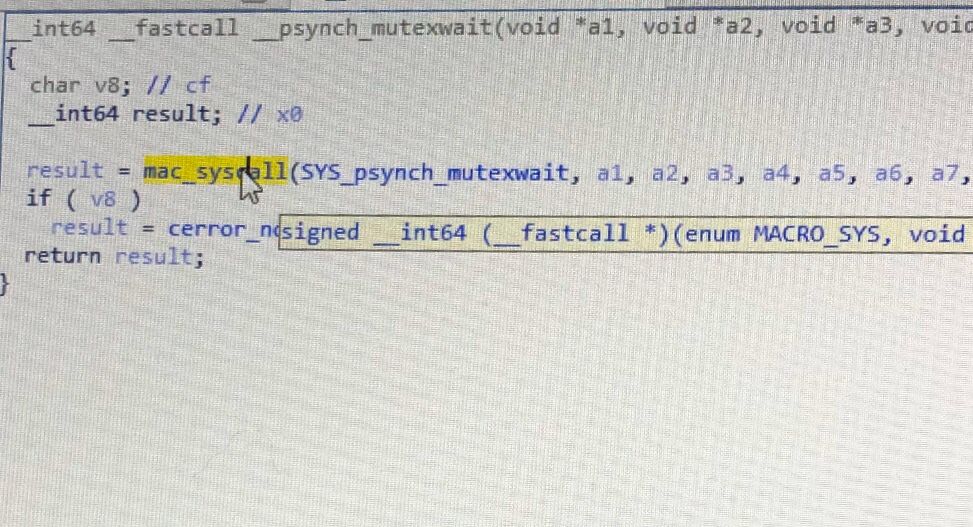
下面根据调用栈,来看一下具体的函数实现。
pthread_mutex_t 如何实现递归
1 | int |
这里有个需要留意的点,就是递归锁的实现。当前的pthread_mutex结构体字段options中会维护一个lockcount,来记录加锁的次数,从而实现递归锁。
如果是递归锁,且已经获得了锁,则至今进入out流程,不会再次进入系统调用的流程。
接下来是等待执行_pthread_mutex_firstfit_lock_wait,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static int
_pthread_mutex_firstfit_lock_wait(_pthread_mutex *mutex, mutex_seq newseq,
uint64_t oldtid)
{
uint64_t *tidaddr;
MUTEX_GETTID_ADDR(mutex, &tidaddr);
uint64_t selfid = _pthread_selfid_direct();
PLOCKSTAT_MUTEX_BLOCK((pthread_mutex_t *)mutex);
do {
uint32_t uval;
do {
PTHREAD_TRACE(psynch_ffmutex_wait | DBG_FUNC_START, mutex,
newseq.lgenval, newseq.ugenval, mutex->mtxopts.value);
uval = __psynch_mutexwait(mutex, newseq.lgenval, newseq.ugenval,
oldtid, mutex->mtxopts.value);
PTHREAD_TRACE(psynch_ffmutex_wait | DBG_FUNC_END, mutex,
uval, 0, 0);
oldtid = os_atomic_load(tidaddr, relaxed);
} while (uval == (uint32_t)-1);
} while (!_pthread_mutex_firstfit_lock_updatebits(mutex, selfid, &newseq));
PLOCKSTAT_MUTEX_BLOCKED((pthread_mutex_t *)mutex, BLOCK_SUCCESS_PLOCKSTAT);
return 0;
}
__psynch_mutexwait被实现在XNU1
2
3
4
5
6/* pthread synchroniser syscalls */
int
psynch_mutexwait(proc_t p, struct psynch_mutexwait_args *uap, uint32_t *retval)
{
return pthread_functions->psynch_mutexwait(p, uap->mutex, uap->mgen, uap->ugen, uap->tid, uap->flags, retval);
}
pthread_functions是pthread向xnu预先注册的一个函数表,与之一起被注册的还有pthread callback1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/*
* pthread_kext_register is called by pthread.kext upon load, it has to provide
* us with a function pointer table of pthread internal calls. In return, this
* file provides it with a table of function pointers it needs.
*/
void
pthread_kext_register(pthread_functions_t fns, pthread_callbacks_t *callbacks)
{
if (pthread_functions != NULL) {
panic("Re-initialisation of pthread kext callbacks.");
}
if (callbacks != NULL) {
*callbacks = &pthread_callbacks;
} else {
panic("pthread_kext_register called without callbacks pointer.");
}
if (fns) {
pthread_functions = fns;
}
}
pthread_kext_register是在libpthread基于mach内核扩展实现(pthread.kext)。这两个参数都非常重要。
pthread_functions_t
1 | const struct pthread_functions_s pthread_internal_functions = { |
pthread_callbacks_t
这个结构体内容很多,有兴趣的点开查看
thread
1 | typedef const struct pthread_callbacks_s { |
其内部会通过系统调用,传递sysCode为SYS_psycnh_mutexwait调用
解锁的流程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/*
* psynch_mutexdrop: This system call is used for unlock postings on contended psynch mutexes.
*/
int
_psynch_mutexdrop(__unused proc_t p, user_addr_t mutex, uint32_t mgen,
uint32_t ugen, uint64_t tid __unused, uint32_t flags, uint32_t *retval)
{
int res;
ksyn_wait_queue_t kwq;
res = ksyn_wqfind(mutex, mgen, ugen, 0, flags, KSYN_WQTYPE_MUTEXDROP, &kwq);
if (res == 0) {
uint32_t updateval = _psynch_mutexdrop_internal(kwq, mgen, ugen, flags);
/* drops the kwq reference */
if (retval) {
*retval = updateval;
}
}
return res;
}
通过上面的pthread_functions_s可以发现,psynch_mutexwait经由XNU系统调用之后,又会回到pthread中的_psynch_mutexwait
_psynch_mutexwait
1 | /* |
核心逻辑在ksyn_wait,通过上面的注释,我们也能知道,走过ksyn_wait之后,就开始出队(drop)了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53int
ksyn_wait(ksyn_wait_queue_t kwq, kwq_queue_type_t kqi, uint32_t lockseq,
int fit, uint64_t abstime, uint16_t kwe_flags,
thread_continue_t continuation, block_hint_t block_hint)
{
thread_t th = current_thread();
uthread_t uth = pthread_kern->get_bsdthread_info(th);
struct turnstile **tstore = NULL;
int res;
assert(continuation != THREAD_CONTINUE_NULL);
ksyn_waitq_element_t kwe = pthread_kern->uthread_get_uukwe(uth);
bzero(kwe, sizeof(*kwe));
kwe->kwe_count = 1;
kwe->kwe_lockseq = lockseq & PTHRW_COUNT_MASK;
kwe->kwe_state = KWE_THREAD_INWAIT;
kwe->kwe_uth = uth;
kwe->kwe_thread = th;
kwe->kwe_flags = kwe_flags;
res = ksyn_queue_insert(kwq, kqi, kwe, lockseq, fit);
if (res != 0) {
//panic("psynch_rw_wrlock: failed to enqueue\n"); // XXX
ksyn_wqunlock(kwq);
return res;
}
PTHREAD_TRACE(psynch_mutex_kwqwait, kwq->kw_addr, kwq->kw_inqueue,
kwq->kw_prepost.count, kwq->kw_intr.count);
if (_kwq_use_turnstile(kwq)) {
// pthread mutexes and rwlocks both (at least sometimes) know their
// owner and can use turnstiles. Otherwise, we pass NULL as the
// tstore to the shims so they wait on the global waitq.
tstore = &kwq->kw_turnstile;
}
pthread_kern->psynch_wait_prepare((uintptr_t)kwq, tstore, kwq->kw_owner,
block_hint, abstime);
ksyn_wqunlock(kwq);
if (tstore) {
pthread_kern->psynch_wait_update_complete(kwq->kw_turnstile);
}
thread_block_parameter(continuation, kwq);
// NOT REACHED
panic("ksyn_wait continuation returned");
__builtin_unreachable();
}
pthread_kern是内核扩展中注册的callback。这里会通过XNU构建一个ksyn_waitq_element_t,然后插入到等待队列ksyn_wait_queue_t中,之后开始进行等待thread_block_parameter
thread_block_parameter
该函数同样被实现在XNU的code>sched_prim.c中。这个文件包含了mach对线程的调度方法。如:thread_run,thread_stop,thread_block等1
2
3
4
5
6
7wait_result_t
thread_block_parameter(
thread_continue_t continuation,
void *parameter)
{
return thread_block_reason(continuation, parameter, AST_NONE);
}
thread_block_reason
1 | /* |
thread_block_reason就是让线程主动让出时间片的流程。并通过thread_select选择一个新的线程继续执行。
接下来看一下解锁的流程。
同样pthread_mutex_unlock最终会调用下的psynch_mutexdrop
pthread_mutex_t 如何实现FIFO
内部会调用 _psynch_mutexdrop_internal1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105/* routine to drop the mutex unlocks , used both for mutexunlock system call and drop during cond wait */
static uint32_t
_psynch_mutexdrop_internal(ksyn_wait_queue_t kwq, uint32_t mgen, uint32_t ugen,
int flags)
{
kern_return_t ret;
uint32_t returnbits = 0;
uint32_t updatebits = 0;
int firstfit = (flags & _PTHREAD_MTX_OPT_POLICY_MASK) ==
_PTHREAD_MTX_OPT_POLICY_FIRSTFIT;
uint32_t nextgen = (ugen + PTHRW_INC);
thread_t old_owner = THREAD_NULL;
ksyn_wqlock(kwq);
kwq->kw_lastunlockseq = (ugen & PTHRW_COUNT_MASK);
redrive:
updatebits = (kwq->kw_highseq & PTHRW_COUNT_MASK) |
(PTH_RWL_EBIT | PTH_RWL_KBIT);
if (firstfit) {
if (kwq->kw_inqueue == 0) {
uint32_t count = kwq->kw_prepost.count + 1;
// Increment the number of preposters we have waiting
_kwq_mark_preposted_wakeup(kwq, count, mgen & PTHRW_COUNT_MASK, 0);
// We don't know the current owner as we've determined this mutex
// drop should have a preposted locker inbound into the kernel but
// we have no way of knowing who it is. When it arrives, the lock
// path will update the turnstile owner and return it to userspace.
old_owner = _kwq_clear_owner(kwq);
pthread_kern->psynch_wait_update_owner(kwq, THREAD_NULL,
&kwq->kw_turnstile);
PTHREAD_TRACE(psynch_mutex_kwqprepost, kwq->kw_addr,
kwq->kw_prepost.lseq, count, 0);
} else {
// signal first waiter
ret = ksyn_mtxsignal(kwq, NULL, updatebits, &old_owner);
if (ret == KERN_NOT_WAITING) {
// <rdar://problem/39093536> ksyn_mtxsignal attempts to signal
// the thread but it sets up the turnstile inheritor first.
// That means we can't redrive the mutex in a loop without
// dropping the wq lock and cleaning up the turnstile state.
ksyn_wqunlock(kwq);
pthread_kern->psynch_wait_cleanup();
_kwq_cleanup_old_owner(&old_owner);
ksyn_wqlock(kwq);
goto redrive;
}
}
} else {
bool prepost = false;
if (kwq->kw_inqueue == 0) {
// No waiters in the queue.
prepost = true;
} else {
uint32_t low_writer = (kwq->kw_ksynqueues[KSYN_QUEUE_WRITE].ksynq_firstnum & PTHRW_COUNT_MASK);
if (low_writer == nextgen) {
/* next seq to be granted found */
/* since the grant could be cv, make sure mutex wait is set incase the thread interrupted out */
ret = ksyn_mtxsignal(kwq, NULL,
updatebits | PTH_RWL_MTX_WAIT, &old_owner);
if (ret == KERN_NOT_WAITING) {
/* interrupt post */
_kwq_mark_interruped_wakeup(kwq, KWQ_INTR_WRITE, 1,
nextgen, updatebits);
}
} else if (is_seqhigher(low_writer, nextgen)) {
prepost = true;
} else {
//__FAILEDUSERTEST__("psynch_mutexdrop_internal: FS mutex unlock sequence higher than the lowest one is queue\n");
ksyn_waitq_element_t kwe;
kwe = ksyn_queue_find_seq(kwq,
&kwq->kw_ksynqueues[KSYN_QUEUE_WRITE], nextgen);
if (kwe != NULL) {
/* next seq to be granted found */
/* since the grant could be cv, make sure mutex wait is set incase the thread interrupted out */
ret = ksyn_mtxsignal(kwq, kwe,
updatebits | PTH_RWL_MTX_WAIT, &old_owner);
if (ret == KERN_NOT_WAITING) {
goto redrive;
}
} else {
prepost = true;
}
}
}
if (prepost) {
if (kwq->kw_prepost.count != 0) {
__FAILEDUSERTEST__("_psynch_mutexdrop_internal: multiple preposts\n");
} else {
_kwq_mark_preposted_wakeup(kwq, 1, nextgen & PTHRW_COUNT_MASK,
0);
}
old_owner = _kwq_clear_owner(kwq);
pthread_kern->psynch_wait_update_owner(kwq, THREAD_NULL,
&kwq->kw_turnstile);
}
}
ksyn_wqunlock(kwq);
pthread_kern->psynch_wait_cleanup();
_kwq_cleanup_old_owner(&old_owner);
ksyn_wqrelease(kwq, 1, KSYN_WQTYPE_MUTEXDROP);
return returnbits;
}
首先系统会维护维护一个全局的等待队列ksyn_wait_queue,在每一个线程执行unlock后,会寻找这个队列的第一个节点,让这个节点获得锁。从而实现FIFO的特性,这也是为什么mutex(公平锁)会比mutex(公平锁)的主要原因。
mutex 总结
- 通过内核扩展注入pthread的操作函数和回调函数。
- pthread_mutex_t 是由bsd实现的互斥锁,通过结构体内部的options中维护lockcount 实现递归。
- 加锁时,通过系统调用进行内核交互(进入内核态)。
- 构建
ksyn_waitq_element_t。 - 将
kwe放入等待队列ksyn_wait_queue_t。 - 调用
ksyn_wait进入thread_block_parameter。 - 使当前线程主动让出时间片,并调用
thread_select选择一个新的线程执行。
- 构建
- 解锁时从
ksyn_wait_queue_t的头部获取一个队列执行。
unfair_lock
同样的来看一组调用栈
os_unfair_lock_lock被定义在libplatform中。1
2
3
4
5
6
7
8
9void
os_unfair_lock_lock(os_unfair_lock_t lock)
{
_os_unfair_lock_t l = (_os_unfair_lock_t)lock;
os_lock_owner_t self = _os_lock_owner_get_self();
bool r = os_atomic_cmpxchg2o(l, oul_value, OS_LOCK_NO_OWNER, self, acquire);
if (likely(r)) return;
return _os_unfair_lock_lock_slow(l, self, OS_UNFAIR_LOCK_NONE);
}
内部直接调用_os_unfair_lock_lock_slow
_os_unfair_lock_lock_slow
1 | OS_NOINLINE |
这里也可以看出os_unfair_lock是不支持递归的,接下来会进行系统调用__ulock_wait,
ulock_wait
ulock_wait的实现在XNU中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289int
ulock_wait(struct proc *p, struct ulock_wait_args *args, int32_t *retval)
{
uint opcode = args->operation & UL_OPCODE_MASK;
uint flags = args->operation & UL_FLAGS_MASK;
if (flags & ULF_WAIT_CANCEL_POINT) {
__pthread_testcancel(1);
}
int ret = 0;
thread_t self = current_thread();
ulk_t key;
/* involved threads - each variable holds +1 ref if not null */
thread_t owner_thread = THREAD_NULL;
thread_t old_owner = THREAD_NULL;
ull_t *unused_ull = NULL;
if ((flags & ULF_WAIT_MASK) != flags) {
ret = EINVAL;
goto munge_retval;
}
bool set_owner = false;
bool xproc = false;
size_t lock_size = sizeof(uint32_t);
int copy_ret;
switch (opcode) {
case UL_UNFAIR_LOCK:
set_owner = true;
break;
case UL_COMPARE_AND_WAIT:
break;
case UL_COMPARE_AND_WAIT64:
lock_size = sizeof(uint64_t);
break;
case UL_COMPARE_AND_WAIT_SHARED:
xproc = true;
break;
case UL_COMPARE_AND_WAIT64_SHARED:
xproc = true;
lock_size = sizeof(uint64_t);
break;
default:
ret = EINVAL;
goto munge_retval;
}
uint64_t value = 0;
if ((args->addr == 0) || (args->addr & (lock_size - 1))) {
ret = EINVAL;
goto munge_retval;
}
if (xproc) {
uint64_t object = 0;
uint64_t offset = 0;
ret = uaddr_findobj(args->addr, &object, &offset);
if (ret) {
ret = EINVAL;
goto munge_retval;
}
key.ulk_key_type = ULK_XPROC;
key.ulk_object = object;
key.ulk_offset = offset;
} else {
key.ulk_key_type = ULK_UADDR;
key.ulk_pid = p->p_pid;
key.ulk_addr = args->addr;
}
if ((flags & ULF_WAIT_ADAPTIVE_SPIN) && set_owner) {
/*
* Attempt the copyin outside of the lock once,
*
* If it doesn't match (which is common), return right away.
*
* If it matches, resolve the current owner, and if it is on core,
* spin a bit waiting for the value to change. If the owner isn't on
* core, or if the value stays stable, then go on with the regular
* blocking code.
*/
uint64_t end = 0;
uint32_t u32;
ret = copyin_atomic32(args->addr, &u32);
if (ret || u32 != args->value) {
goto munge_retval;
}
for (;;) {
if (owner_thread == NULL && ulock_resolve_owner(u32, &owner_thread) != 0) {
break;
}
/* owner_thread may have a +1 starting here */
if (!machine_thread_on_core(owner_thread)) {
break;
}
if (end == 0) {
clock_interval_to_deadline(ulock_adaptive_spin_usecs,
NSEC_PER_USEC, &end);
} else if (mach_absolute_time() > end) {
break;
}
if (copyin_atomic32_wait_if_equals(args->addr, u32) != 0) {
goto munge_retval;
}
}
}
ull_t *ull = ull_get(&key, 0, &unused_ull);
if (ull == NULL) {
ret = ENOMEM;
goto munge_retval;
}
/* ull is locked */
ull->ull_nwaiters++;
if (ull->ull_opcode == 0) {
ull->ull_opcode = opcode;
} else if (ull->ull_opcode != opcode) {
ret = EDOM;
goto out_locked;
}
/*
* We don't want this copyin to get wedged behind VM operations,
* but we have to read the userspace value under the ull lock for correctness.
*
* Until <rdar://problem/24999882> exists,
* holding the ull spinlock across copyin forces any
* vm_fault we encounter to fail.
*/
/* copyin_atomicXX always checks alignment */
if (lock_size == 4) {
uint32_t u32;
copy_ret = copyin_atomic32(args->addr, &u32);
value = u32;
} else {
copy_ret = copyin_atomic64(args->addr, &value);
}
#if DEVELOPMENT || DEBUG
/* Occasionally simulate copyin finding the user address paged out */
if (((ull_simulate_copyin_fault == p->p_pid) || (ull_simulate_copyin_fault == 1)) && (copy_ret == 0)) {
static _Atomic int fault_inject = 0;
if (os_atomic_inc_orig(&fault_inject, relaxed) % 73 == 0) {
copy_ret = EFAULT;
}
}
#endif
if (copy_ret != 0) {
/* copyin() will return an error if the access to the user addr would have faulted,
* so just return and let the user level code fault it in.
*/
ret = copy_ret;
goto out_locked;
}
if (value != args->value) {
/* Lock value has changed from expected so bail out */
goto out_locked;
}
if (set_owner) {
if (owner_thread == THREAD_NULL) {
ret = ulock_resolve_owner(args->value, &owner_thread);
if (ret == EOWNERDEAD) {
/*
* Translation failed - even though the lock value is up to date,
* whatever was stored in the lock wasn't actually a thread port.
*/
goto out_locked;
}
/* HACK: don't bail on MACH_PORT_DEAD, to avoid blowing up the no-tsd pthread lock */
ret = 0;
}
/* owner_thread has a +1 reference */
/*
* At this point, I know:
* a) owner_thread is definitely the current owner, because I just read the value
* b) owner_thread is either:
* i) holding the user lock or
* ii) has just unlocked the user lock after I looked
* and is heading toward the kernel to call ull_wake.
* If so, it's going to have to wait for the ull mutex.
*
* Therefore, I can ask the turnstile to promote its priority, and I can rely
* on it to come by later to issue the wakeup and lose its promotion.
*/
/* Return the +1 ref from the ull_owner field */
old_owner = ull->ull_owner;
ull->ull_owner = THREAD_NULL;
if (owner_thread != THREAD_NULL) {
/* The ull_owner field now owns a +1 ref on owner_thread */
thread_reference(owner_thread);
ull->ull_owner = owner_thread;
}
}
wait_result_t wr;
uint32_t timeout = args->timeout;
uint64_t deadline = TIMEOUT_WAIT_FOREVER;
wait_interrupt_t interruptible = THREAD_ABORTSAFE;
struct turnstile *ts;
ts = turnstile_prepare((uintptr_t)ull, &ull->ull_turnstile,
TURNSTILE_NULL, TURNSTILE_ULOCK);
thread_set_pending_block_hint(self, kThreadWaitUserLock);
if (flags & ULF_WAIT_WORKQ_DATA_CONTENTION) {
interruptible |= THREAD_WAIT_NOREPORT;
}
if (timeout) {
clock_interval_to_deadline(timeout, NSEC_PER_USEC, &deadline);
}
turnstile_update_inheritor(ts, owner_thread,
(TURNSTILE_DELAYED_UPDATE | TURNSTILE_INHERITOR_THREAD));
wr = waitq_assert_wait64(&ts->ts_waitq, CAST_EVENT64_T(ULOCK_TO_EVENT(ull)),
interruptible, deadline);
ull_unlock(ull);
if (unused_ull) {
ull_free(unused_ull);
unused_ull = NULL;
}
turnstile_update_inheritor_complete(ts, TURNSTILE_INTERLOCK_NOT_HELD);
if (wr == THREAD_WAITING) {
uthread_t uthread = (uthread_t)get_bsdthread_info(self);
uthread->uu_save.uus_ulock_wait_data.retval = retval;
uthread->uu_save.uus_ulock_wait_data.flags = flags;
uthread->uu_save.uus_ulock_wait_data.owner_thread = owner_thread;
uthread->uu_save.uus_ulock_wait_data.old_owner = old_owner;
if (set_owner && owner_thread != THREAD_NULL) {
thread_handoff_parameter(owner_thread, ulock_wait_continue, ull);
} else {
assert(owner_thread == THREAD_NULL);
thread_block_parameter(ulock_wait_continue, ull);
}
/* NOT REACHED */
}
ret = wait_result_to_return_code(wr);
ull_lock(ull);
turnstile_complete((uintptr_t)ull, &ull->ull_turnstile, NULL, TURNSTILE_ULOCK);
out_locked:
ulock_wait_cleanup(ull, owner_thread, old_owner, retval);
owner_thread = NULL;
if (unused_ull) {
ull_free(unused_ull);
unused_ull = NULL;
}
assert(*retval >= 0);
munge_retval:
if (owner_thread) {
thread_deallocate(owner_thread);
}
if (ret == ESTALE) {
ret = 0;
}
if ((flags & ULF_NO_ERRNO) && (ret != 0)) {
*retval = -ret;
ret = 0;
}
return ret;
}
这里我们有看到了熟悉的thread_block_reason函数。
我们看到os_unfair_lock的是直接依赖CPU的调度执行的,来看下面的调用栈。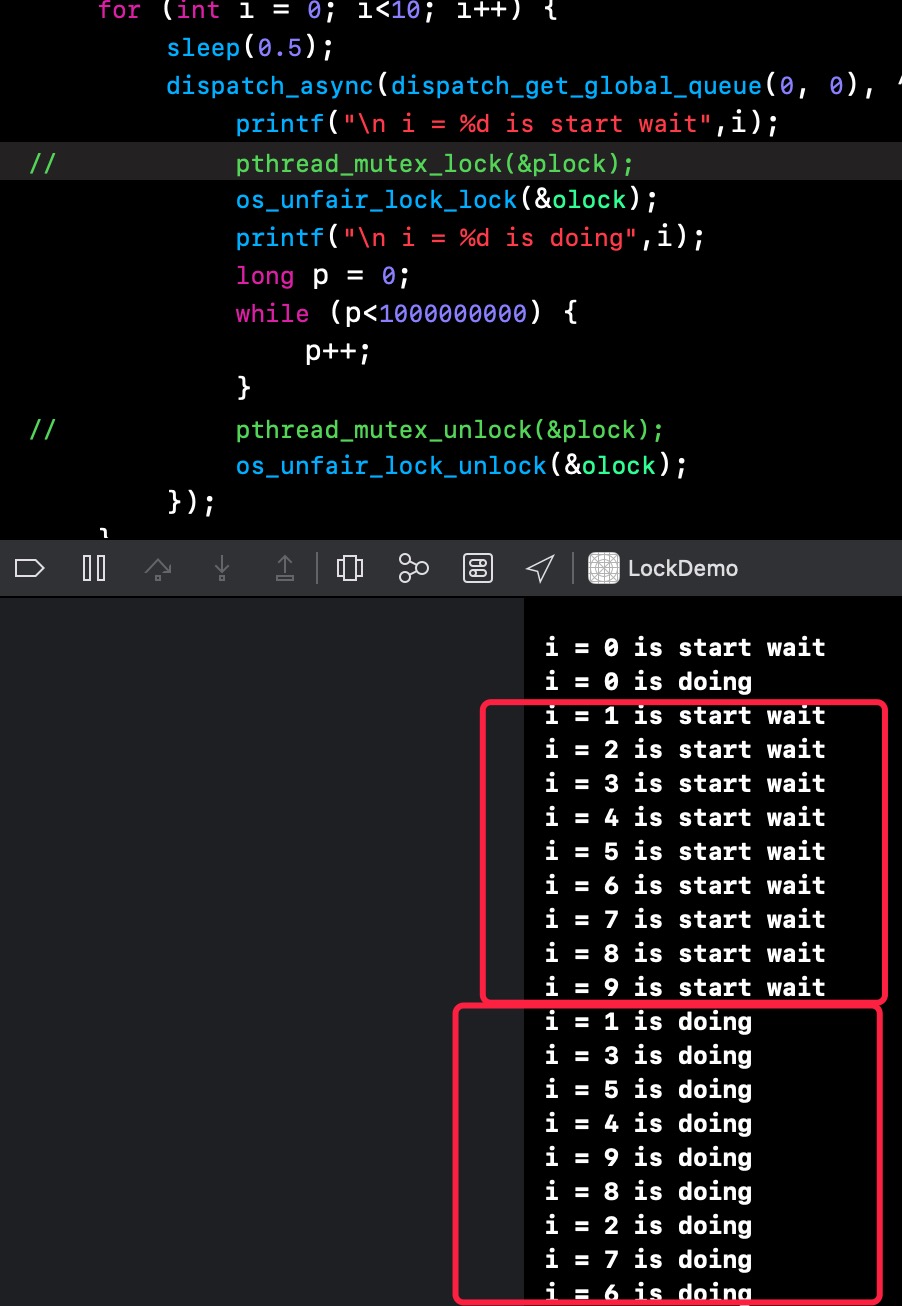
os_unfair_lock 总结
作为非公平锁的实现,os_unfair_lock直接有CPU来调度,不会像mutex那样保证等待队列的出列顺序,也就减少了线程切换的资源消耗。
对比 mutex:
优点:
- 申请锁的内存消耗更少,
os_unfair_lock为int32,而mutex的结构体显然比os_unfair_lock大 - 减少由于要保持队列顺序,而产生线程上下文切换带来的消耗。
缺点:
- 无法保证被锁住线程的执行顺序。很可能会出现某个线程长时间不会执行的情况
锁的使用场景
- 当每个锁的开销很重要时(比如会申请大量的锁),并且不需要在乎任务的执行顺序。就选
os_unfair_lock吧。 - DispatchQueue的同步前文已经分析过了。他使用起来非常方便。而且苹果主推(你懂得)。对于同步和锁的控制也相当简单。GCD应该作为同步手段的默认选项。
pthread_mutex就处在上面两者的选择中间,如果想保证线程的执行顺序,以及想其他递归,条件等功能。可以选择mutex